Actualidad
Altitud de la frontera de Chile (Le Wagon Chile)
Hoy les presentamos los resultados de un proyecto que hemos realizado conjunto con nuestros aliados de Le Wagon Chile. Para ver la infografía en pantalla grande (PDF), hacer clic en la imagen:
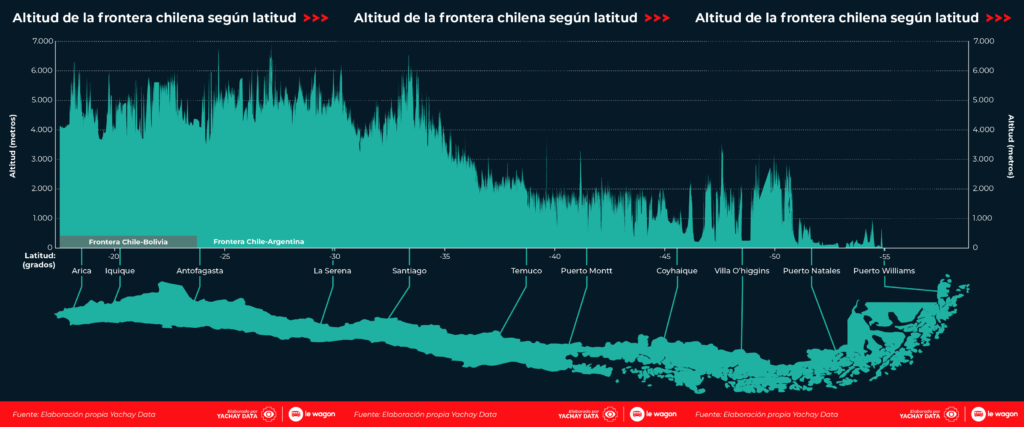
Eje x: latitud (de norte a sur).
Eje y: altitud de la frontera cordillerana de Chile con Bolivia, y luego con Argentina, en función de la latitud.
¿Cómo se realizó el proyecto?
Primero, descargamos el mapa de las fronteras de Chile (la versión de DIFROL), filtramos las fronteras Bolivia-Chile y Argentina-Chile (python-geopandas). Así obtuvimos una nube de puntos de la ubicación (latitud,longitud). Finalmente, para cada punto (latitud,longitud), usamos la librería request en paralelo), para obtener de forma automática en la web la altitud de cada punto. Se ploteo “max(alitud)” en función de latitud y listo! (sin olvidar el trabajo de diseño para que se viera más bonito!!!)
Observaciones: Se hace evidente el hecho de que hacia el sur la cordillera se hace más baja. Algunas veces, la altitud se estanca: son lagos jaja! ¿Los ven, en el sur por ejemplo?
Pronto se publicará el código fuente de este proyecto, ¡así que atentos!

Hoy quisimos hablar un poco de Web Scraping. ¿De qué se trata?
El Web Scraping agrupa los métodos de extracción de datos en la web:
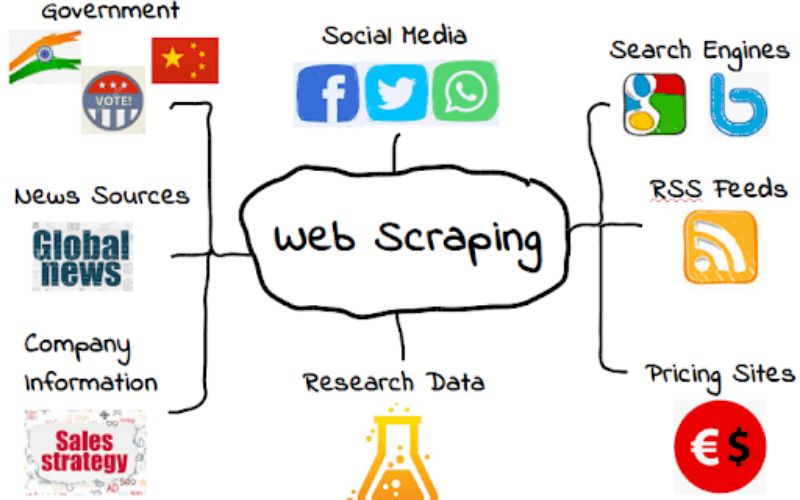
Los sitios web tienen mucha información relevante. A veces, esta puede ser exportada directamente como Excel .xlsx, un archivo separado por comas .csv u otras extensiones comunes. Como ejemplo, mencionamos a Our World In Data, que está hecho para ser de uso simple. En un par de clics, uno puede generar distintas visualizaciones y acceder a los datos en varios formatos.
Otras veces, se ponen a disposición APIs, que permiten recuperar la información directamente. Por ejemplo, Uber tiene una (ver ahí). Con una línea de código, uno puede enviar solicitudes “requests”, y obtener información de tráfico, de precios, entre otros.
Pero, en la mayoría de los casos, el sitio no está hecho para que uno pueda recolectar información. Ahí llega el mundo del Web Scraping.
Además, el Web Scraping está muy relacionado con el manejo de tareas repetitivas. La misma pregunta vuelve siempre: ¿Vale la pena armar código para automatizar la recuperación de datos? ¿O es mejor hacerlo manual?
La herramientas de Web Scraping se justifican cuando la recolección de datos manual requeriría demasiado recursos (tiempo, energía…). Como muchas veces, esto depende de trade-offs.
Sigamos un poco con las herramientas disponibles. Dependiendo del sitio web scrapeado, uno puede usar distintas librerías. En general, se usan librerías de Python para hacer Web Scraping (también existen librerías para Node.js).
Las librerías que más se usan son requests, selenium, beautifulsoup o scrapy. Permiten navegar en las páginas web, y recuperar la información deseada, al acceder a los elementos del html.
Si necesitas ayuda para armar este tipo de herramientas, nos puedes escribir a contacto@yachaygroup.com. Si quieres aprender a programar en Python, inscríbete a los cursos Le Wagon (contáctanos si quieres beneficiar del descuento 15% Yachay por correo, o a nuestra página Instagram).